Board Incident Response Oversight. How to Avoid the Two Worst Words: “We Assumed”
Board Incident Response Oversight helps you kill 'we assumed' with proof, clear decision rights, metrics, and quarterly drills for faster recovery.


A cybersecurity incident isn't the rare event anymore. With cyber threats evolving rapidly, it's the fire drill you don't get to schedule. The real failure isn't that something happened, it's that leadership got surprised by basics. Those surprises often show up as two words you never want in the boardroom: "We assumed."
You assumed backups worked, but nobody tested restores. You assumed a vendor would tell you fast, but the contract didn't require it. You assumed legal and comms were aligned, but they hadn't met since last year. Each assumption adds time, noise, and cybersecurity risk, especially when a data breach puts trust, disclosure duties, and business continuity on the line.
Board Incident Response Oversight is your job of setting expectations, funding readiness, and verifying proof, without running the technical response. Your cybersecurity strategy ensures the company can make clear decisions under pressure, communicate honestly, and recover fast enough to protect customers and the business.
You'll walk away with a practical oversight checklist, the right metrics, and a cadence that keeps gaps from hiding in plain sight.
Key takeaways
You're accountable for governance and disclosure readiness, not command-and-control of the response team.
The fastest incidents are the ones where decision rights were settled before the crisis.
If you can't point to evidence (tests, reports, contracts), you're relying on hope.
Shared responsibility in cloud and vendors is where "we assumed" grows best.
A one-page dashboard with trends beats a thick deck with opinions.
Quarterly decision drills reduce chaos and speed up executive calls.
In the first 72 hours, your discipline around facts and documentation protects the company.
What your board is accountable for in incident response, and what it can delegate
Your board's job is to govern. Management's job is to execute. That line sounds obvious until an incident hits and everyone starts trying to "help." The board can't delegate accountability for oversight of material risk, readiness funding, and disclosure posture, including SEC rules and disclosure compliance. On the other hand, you also can't run the response like an operations team. This stems from your fiduciary responsibility as directors.
Think of it like a ship in a storm. You set the destination, safety rules, and what risks are acceptable. The captain and crew handle the sails, engines, and navigation in real time. If the board grabs the wheel mid-storm, you create confusion, not safety.
Here's what you own as a director:
Set expectations for incident readiness (testing, training, time-to-recover goals).
Approve funding that matches the risk appetite you say you have.
Require proof, not confidence, that plans work.
Oversee material risk and disclosure practices, including escalation to the board, as part of your risk management strategy.
Here's what you should not do:
Direct engineers on containment steps.
Argue tools and architectures during live response.
Freelance external communications.
Boards get trapped by assumptions when they accept "we have a plan" without asking what was tested, what failed, and what changed. Another common trap is mistaking policy for capability. A written incident plan doesn't mean you can restore a critical database on a Sunday night. This connects incident response to your broader Enterprise Risk Management framework.
If you need a practical model for bridging governance and execution, such as reviewing your governance charters, working with an experienced CISO for hire can help translate operational reality into board-level decisions you can stand behind. This reinforces board oversight in distinguishing it from management oversight.
The oversight sweet spot: decisions only you can make
Some choices are too important to leave fuzzy, because they shape every incident outcome.
Risk tolerance for downtime and data loss: If you never defined tolerance, teams will guess under stress, and guesses become outages.
Incident disclosure principles and thresholds: If "material" is unclear internally, you'll either delay too long or disclose in a scramble.
Crisis communications guardrails: If you didn't pre-approve what "we can say" looks like, someone will say too much or too little.
Third-party risk posture expectations: If vendor standards are vague, you'll assume they have controls you never verified.
Accountability for readiness testing: If testing ownership isn't explicit, exercises slip, and nobody feels responsible.
When to bring in outside counsel and forensics: If the trigger is unclear, you'll wait, lose evidence, and complicate privilege.
If you want to banish "we assumed," make the board's must-decide items explicit, then ask for evidence that management built around them.
A clean RACI for incidents so nobody guesses in the heat of the moment
You don't need a perfect chart to get value, you need clear decision rights.
In plain terms, your RACI should read like this:
Board: Accountable for oversight, disclosure readiness, and approving exceptional actions (ransom payment posture, major shutdown tradeoffs, public risk statements).
CEO: Accountable for enterprise command, business continuity priorities, and final go-forward decisions during disruption.
General Counsel (GC): Accountable for legal strategy, privilege approach, regulator engagement posture, and outside counsel coordination.
CISO: Responsible for security response leadership, threat containment, investigation coordination, and technical status reporting.
CIO/CTO: Responsible for IT service restoration, system shutdown execution, and recovery sequencing.
Comms (PR/Marketing): Responsible for drafting internal and external messaging within approved guardrails.
HR: Responsible for employee communications, insider-related coordination, and workforce actions if needed.
Key vendors (cloud, MDR, forensics, IR retainers): Responsible for contracted response actions, logging access, and time-bound notifications.
Be explicit about who decides: shutting systems down, paying a ransom, notifying regulators, and sending customer notices. This reduces meeting chaos and speeds decisions when minutes matter.
Replace assumptions with proof: the board questions that surface gaps early
The best oversight questions feel almost too simple. That's the point. Simple questions force concrete answers, and concrete answers require evidence.
You're looking for outputs you can touch: after-action reports, test results, restore logs, contract clauses, and escalation records. Opinions and slideware don't survive incidents.
Ask questions in themes, and don't accept "we're working on it" without dates and owners. If a leader can't show progress over two quarters, it's not a priority, even if they say it is.
A helpful discipline is to end each line of questioning with: "What proof would you show me if I were skeptical?" That single habit flushes out weak spots fast and reveals your organization's cyber maturity.
When you want more executive-grade prompts like these, you can pull from CISO business insights that frame cyber readiness in business terms.
Preparedness questions that force clarity before the crisis
Start with what will break first: people, process, or technology.
When did you last run a full exercise with executives, what broke, and what changed after? (Ask for the after-action report and the closed action list.)
What are your target times to detect, contain, and recover, and how do you measure them? (Ask for trend charts tied to real incidents or drills.)
Which systems are your crown jewels, and do you have tested backups for them? (Ask for restore test evidence for those specific systems, not a general statement.)
Who is on call 24/7, and what happens if the first two people are unavailable? (Ask for the on-call roster, escalation path, and cross-training proof.)
Where is your single source of truth during an incident? (Ask to see the runbook and the tool or channel used for executive updates.)
What's your policy on paying ransoms, and how does it translate into a decision process? (Ask for the decision tree and the list of required approvals.)
You're not trying to "catch" your team. Through management oversight, you're trying to prevent the silent failure where everyone believes someone else tested the hard parts.
Third-party risk management and cloud questions that prevent "we thought they had it"
Assumptions multiply at the seams. Vendors, SaaS apps, cloud platforms, and managed services can fail in ways your customers still blame on you.
Ask cybersecurity questions that map dependency to business impact:
Which vendors can take you down, and what's the fallback if they do? (Ask for a dependency map and the continuity workaround.)
Do contracts require incident notice within a defined time, and do you test that process? (Ask for the contract clause and evidence of notice drills.)
In your cloud setup, who owns logs, retention, and forensics access? (Ask for the logging standard, retention settings, and access approvals.)
If a vendor is the breach source but your customers blame you, what's your plan? (Ask for pre-drafted customer language and a joint comms playbook.)
Do you have an incident response retainer, and what are the response times? (Ask for the SLA and the activation steps.)
Shared responsibility is not shared accountability. If customers suffer, you own the outcome, even when a vendor caused the trigger.
Design a board ready incident rhythm: reporting, exercises, and decision drills
Oversight fails when it's "once a year" work. At the same time, you don't want to bury the board in operational detail. The answer is a steady rhythm that keeps readiness visible, makes progress measurable, and turns incident decisions into muscle memory.
A practical cadence looks like this:
Quarterly: one-page dashboard, plus one executive scenario drill.
Quarterly (audit committee): deeper review in audit committee (top risks, open findings, vendor exposure).
Annually: a deep dive on incident readiness, including a live decision exercise with the full board.
This rhythm also supports trust. When you treat incident readiness like financial controls, you show regulators and stakeholders that the company takes governance seriously. That's a core theme of being a digital trust expert, because trust comes from repeatable behavior, not promises.
Your incident dashboard should answer: Are we ready, are we improving, are we honest?
Track key cybersecurity metrics with targets and trends to set context. Then focus discussion on exceptions, especially for cybersecurity preparedness.
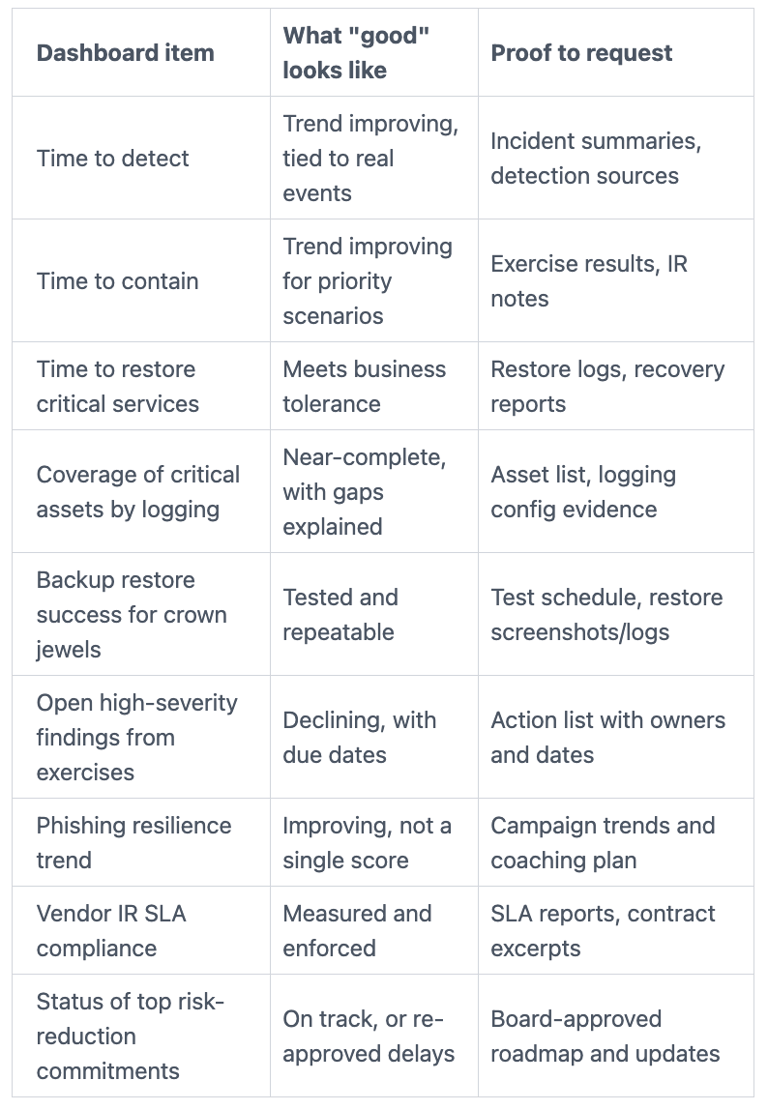
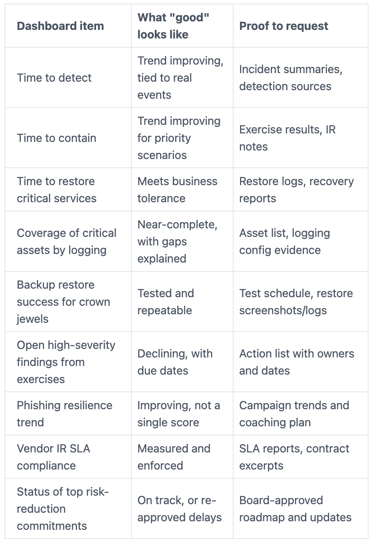
Avoid vanity metrics like "number of alerts" without meaning. Ask for trends, targets, and the story behind exceptions.
Run one executive tabletop exercise each quarter, and rotate the hard ones
Pick scenarios that force tradeoffs, not trivia. Rotate through:
Ransomware with partial backups
Cloud identity compromise
Data leak extortion
Third-party outage that stops revenue
Insider misuse tied to a sensitive role
Social engineering targeting executives
Make each drill a decision drill. Practice shutdown calls, statement timing, customer notifications, regulator notifications, and how you handle conflicting advice from IT, legal, and operations.
End every exercise with a short action list: owner, due date, and the risk if it slips. Then follow up until it closes. Otherwise, you're running theater, not improving readiness.
When an incident hits: a simple board playbook to avoid "we assumed" in real time
In the first 24 to 72 hours, the board's goal is disciplined oversight. You help management stay focused, protect the company legally, and make high-impact decisions on material cybersecurity incidents with the best available facts.
Your incident response playbook should be calm and repeatable, even when the incident isn't.
If you want leaders who are trained to operate this way under pressure, it helps when your security leadership is grounded in the NIST Cybersecurity Framework and real-world execution, not just theory. That's the point behind being certified to lead across governance, risk, and incident response.
First 24 hours: get the facts, protect privilege, stabilize the business
Start by confirming who is in command (often the CEO, supported by CISO, CIO, and GC). Next, align on whether you need outside counsel and forensics now, not later. Early engagement can protect sensitive work under privilege and preserve evidence.
Then lock down a single source of truth for executive updates. Agree on what is known, what is suspected, and what is still unknown. Push the team to label uncertainties clearly.
Confirm containment actions and business continuity steps. You're not approving firewall rules, but you may approve a major shutdown that protects customers while hurting revenue.
Set an update cadence that matches the situation, often twice daily early on. Finally, document key decisions and why you made them. That record matters later.
Days 2 and 3: validate impact, plan communications, and lock in lessons learned
By day two, you should push for an impact assessment that connects tech facts to business reality. What data types are involved, what systems are affected, and what operations are at risk? Ask for confidence levels, not guesses.
Next, align communications. Internal messaging, customer statements, and regulator notices such as a Form 8-K (triggered by materiality analysis) should match. Make sure legal and comms agree on wording and timing, and avoid speculation.
If the company will operate in a workaround mode, confirm the plan, risks, and time limits. Workarounds often become the next incident if they linger.
Before the week ends, require a post-incident review with root cause, control gaps, and a funded remediation plan. That's how assumptions turn into documented facts, decisions, and improvements.
Conclusion: turn assumptions into oversight you can defend
Strong Board Incident Response Oversight isn't about fear. It's about building cyber resilience through preparedness, faster decisions, and trust you can earn again after a bad day.
Bring this practical checklist to your next board or committee meeting:
Confirm incident decision rights (shutdowns, ransom, notifications).
Approve downtime and data-loss tolerance for crown jewels.
Require quarterly executive scenario drills, with follow-up to close actions.
Review backup restore test evidence for critical systems.
Validate logging coverage and retention for key assets and cloud services.
Confirm vendor incident notice timelines exist in contracts and are tested.
Review time-to-detect, contain, and restore trends, plus exceptions.
Ensure outside counsel and forensics triggers are written and understood.
Require a single source of truth process for incident updates.
Fund the top cybersecurity risk-reduction commitments you expect to see delivered.
FAQs
What should you ask for after an incident?
Ask for a timeline, decisions made, evidence preserved, customer impact, and a remediation plan with owners, costs, and dates.
How often should you run tabletop exercises?
Quarterly is a strong baseline for executive decision drills, with an annual deep dive that involves the full board.
What metrics matter most to directors?
Time to detect, contain, and restore, crown jewel backup restore success, logging coverage, open high-severity findings, and vendor response performance.
When should you involve outside counsel and forensics?
Bring them in when data exposure is plausible, extortion is involved, privilege matters, or you lack confidence in in-house evidence collection.
How should you handle vendor-caused incidents?
Treat them as your cybersecurity incident for customer trust purposes. Enforce notice SLAs, secure forensics access, and coordinate messaging before customers hear it elsewhere.
If you want a steadier cadence, clearer proof, and less guesswork, you can engage fractional CISO support to tighten incident response oversight and readiness before the next test arrives.
Providing plain-English technology oversight to help Boards and CEOs lead with confidence and make defensible risk decisions.
© 2026. All rights reserved.
Navigation
Free Resources
Contact
Stay ahead of your next board agenda
Sign up for Reports & Learnings From the Boardroom. Plain-English AI and cyber governance insights, biweekly. No pitch.
No spam. Unsubscribe anytime. · Or download the Director's AI Question Pack — 25 questions free