How to Measure Cybersecurity Program Effectiveness in 90 Days
Learn how to measure cybersecurity program effectiveness in 90 days with a simple scorecard tied to top risks, trends, and proof you can show the board.


If you can't explain whether security is working, you're stuck in a bad spot. You either over-invest to feel safe, or under-invest until something breaks. Meanwhile, your board wants confidence, your customers expect uptime, and your teams need clear decisions.
The good news is you don't need a new tool stack to get clarity fast. You need a short window, a tight scorecard, and proof you can inspect. In the next 90 days, you can move from "we think we're fine" to "here's what's improving, here's what's exposed, and here's what we're doing next."
This plan shows how to measure cybersecurity program effectiveness using outcomes you can verify, not a list of products. You'll define what "effective" means for your business, build a compact set of metrics, then turn those numbers into decisions leaders can stand behind.
Key takeaways you can use this week
Define effectiveness in business terms (revenue protection, uptime, trust), so metrics don't drift into technical noise.
Write three outcome statements you can test within 90 days, not "maturity goals" that take a year.
Pick a small scorecard (8 to 12 metrics) that covers exposure, response speed, recovery strength, and governance.
Validate the data source for each metric and name an owner, so you can defend numbers under pressure.
Run a 30-60-90 cadence that produces a first dashboard quickly, then improves it with evidence and tests.
Report trends and decisions, not activity, so executives understand what changed and what you need from them.
Tie each metric to a decision right (accept, reduce, transfer, or avoid risk), so measurement drives action.
Start with what "effective" means for your business, not your tools
Security measurement fails when it starts with controls. You end up counting patches, alerts, and training completions, then hoping it adds up to safety. It rarely does. Instead, start where leadership already cares: money, operations, and reputation.
First, translate business goals into outcomes you can observe. If growth depends on a reliable customer portal, then "effective" includes fewer high-risk exposures on that platform and faster recovery when something breaks. If you're entering regulated markets, then "effective" includes faster evidence production and fewer repeat audit findings, but also fewer outages and fewer privacy incidents.
Next, get decision rights on paper. Who can accept risk for a product launch? Who can approve an exception to MFA? Who decides whether to pay for containment help during an incident? If you can't answer those, your metrics won't lead anywhere, because no one is accountable for the decision they imply.
Also separate compliance from readiness. Compliance tells you you met a standard at a point in time. Readiness tells you you can keep the business running when something goes wrong. You want both, but you measure them differently. If you're trying to shift that mindset, anchor the conversation in compliance as a catalyst for confidence, not as a quarterly scramble.
Finally, avoid vanity metrics. "Phishing clicks fell" sounds good, yet it may not change breach risk if privileged accounts still lack MFA. If a metric doesn't change a decision, it's trivia.
If a metric can't trigger a decision, it won't earn attention for long.
Write three outcome statements you can actually test in 90 days
Keep these short, testable, and tied to business impact. Here are three you can copy and adjust:
Contain high-severity incidents faster: "Reduce time to contain high-severity incidents to under 24 hours." This protects revenue by limiting downtime and fraud spread.
Prove you can restore critical services: "Restore your top two customer-facing services from backups within your stated recovery time objective." This supports uptime and keeps customers from losing trust.
Shrink critical asset exposure: "Cut critical internet-facing findings older than 30 days by 50%." This reduces the open door time attackers rely on.
Each statement has a finish line. You can test it, show evidence, and track trend.
Agree on a risk baseline so your numbers mean something
Metrics without a baseline are like a speedometer without a road. You need a lightweight starting point so improvement is real.
In one working session, define your "crown jewels" (systems, data, and processes that keep you alive). Then list top threats that match your reality, such as ransomware, vendor compromise, account takeover, or data leakage. Capture the current gaps that matter most, even if the list is imperfect.
Use a simple structure like NIST CSF or ISO 27001 to keep categories consistent. Don't aim for perfect scoring. Aim for repeatable classification, so you can compare month to month without changing the ruler.
Pick a small scorecard that shows coverage, speed, and impact
A 90-day scorecard should feel like a cockpit, not a novel. If you track 40 metrics, you'll drown in definitions and arguments. If you track five, you'll miss blind spots. A practical range is 8 to 12, grouped into themes executives understand.
Before the table, decide "good" in plain terms. For example, "MFA on 100% of privileged accounts" is clear. "Improve identity posture" is not. Then make every metric auditable: one system of record, one formula, one owner, and a stated update frequency.
Here's a compact scorecard you can start with:
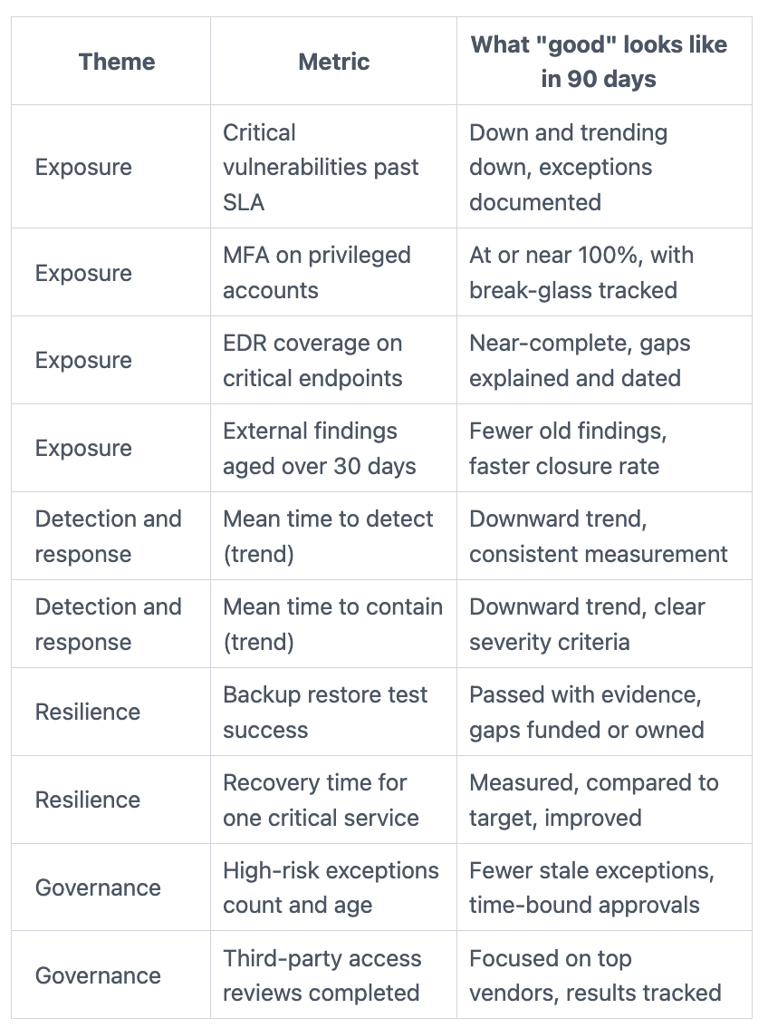
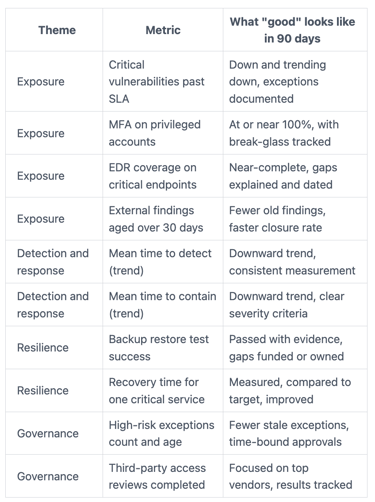
The point isn't to look perfect. The point is to show where you're exposed, how fast you can react, and whether recovery is real. If you want a stronger executive framing for this, build on the ideas in finding the hidden value of cyber metrics, where the story matters as much as the number.
Use leading indicators to prevent problems, not just explain them
Leading indicators tell you what's likely to happen next. They're your smoke alarms. In practice, they include coverage and hygiene metrics that predict breach paths.
For example, track critical patch SLA coverage on crown jewel systems. Add MFA coverage for privileged accounts, because that blocks common takeover routes. Watch EDR coverage on endpoints that can reach sensitive data. Finally, track attack surface findings aged over 30 days, since old issues signal a backlog that attackers love.
Review leading indicators weekly for the first month, then bi-weekly once the numbers stabilize. Most teams improve simply by naming an owner and publishing the trend.
Use lagging indicators to show business impact when things go wrong
Lagging indicators tell you what already happened. They matter because leaders remember outages and headlines. Still, a single number can mislead, so emphasize trends and context.
Use mean time to detect and mean time to contain by severity band. Add downtime hours caused by security events, even if you start with estimates. If you have ransomware exposure, measure recovery time during a restore test, then compare it to your stated goal. When you can, include cost ranges (investigation hours, external support, lost revenue bands). You're not trying to predict pennies, you're trying to guide decisions.
Run a 30-60-90 plan that turns metrics into decisions leaders can inspect
Think of the 90 days like building a trustworthy instrument panel in a car. First, you wire the sensors. Next, you check they read correctly. Then you drive and adjust based on what you see.
Your guiding rule is evidence. Every metric should tie back to logs, tickets, or test results you can produce on request. Every metric also needs an action path, so red means something besides "panic."
When you're preparing for incident pressure, your measurement approach should also work during a crisis. The same discipline applies: a few numbers, updated often, tied to decisions. If you want a model for that style of reporting, use command center metrics that inspire confidence as a reference for what leadership can absorb when stress is high.
Days 1 to 30: clean up data, define owners, and publish a first draft dashboard
Start by picking your systems of record. For most organizations, that's a ticketing system, an identity directory, endpoint management, vulnerability scanning, and backup or recovery tooling. Don't integrate everything. Just pick the sources you trust most.
Then define metric formulas in one page. Write them in plain language, including scope rules (what counts as "critical," what's excluded, and why). Name an owner for each metric, usually the leader who can fix what the metric reveals.
Set targets that match your baseline. If you're at 40% MFA coverage on privileged accounts, don't promise 100% in two weeks. Promise a trend and a date, then show progress.
Publish a first draft dashboard by day 30, even if it's ugly. A dashboard you can improve beats one you never ship. Quick wins often come from critical asset inventory and account hygiene (stale admins, shared accounts, and weak joiner-mover-leaver steps).
Days 31 to 90: prove readiness with one high value test and a better exec narrative
In this window, pick one proof exercise that matters to the business. Keep it focused and document everything.
Good choices include a ransomware recovery test for one critical service, an incident response tabletop with executives, or a third-party access review of a key vendor with deep connectivity. Choose the one that reduces doubt fastest.
After the test, convert results into decisions. If recovery time misses the goal, you may need immutable backups, better segmentation, or more staff coverage. If the tabletop shows slow decision-making, you may need clearer roles, pre-approved communications, or a simpler escalation path.
Your narrative should answer three executive questions: What changed? What risk remains? What do you need from us? That's how metrics turn into budget, staffing, and policy choices instead of another report.
FAQs leaders ask when they want proof fast
How many metrics is enough?
Eight to twelve is usually enough. Fewer misses blind spots, more becomes noise.
What if your data is messy?
Start with one trusted source per metric. Document gaps and improve them over 90 days.
How do you compare across business units?
Use the same definitions and scopes, then normalize by asset criticality, not headcount.
What should you show the board?
Show trend, top exposures, readiness test results, and decisions needed. Skip tool details.
Can you do this without buying new tools?
Yes. Most metrics come from identity, ticketing, endpoint management, and backup systems you already have.
How do you avoid metric gaming?
Use auditable sources, keep definitions stable, and pair numbers with spot checks and tests.
What if you're in M&A or a major change?
Measure integration risk directly (identity alignment, asset discovery, vendor access, and recovery readiness) and expect baselines to shift.
How often should you refresh targets?
Review targets quarterly, or after major changes. Update slowly so trends stay meaningful.
Conclusion
In 90 days, you can move from opinion to proof. Start by defining what "effective" means for your business, then write a few outcomes you can test. Build a small scorecard that covers exposure, response speed, recovery strength, and governance. Finally, run a 30-60-90 cadence that produces evidence and decisions leaders can inspect.
If you want momentum, pick one high-value test and schedule it now. A real restore or a serious tabletop will tell you more than a dozen slide decks.
When you need an experienced partner to tighten the scorecard, validate the story, and make board reporting clearer, consider engaging a CISO advisor who can help you turn metrics into confident action. Your next 90 days can be measurable, defensible, and calm.
Tyson Martin is the executive public and pre-IPO companies in financial services, AI/data, SaaS, and cloud hire to make trust a measurable asset, one accountable answer to Is it secure? Is it resilient? Is the AI governed?
© 2026. All rights reserved.
Navigation
Free Resources
Contact
Stay ahead of your next board agenda
Sign up for Reports & Learnings From the Boardroom. Plain-English AI and cyber governance insights, biweekly. No pitch.
No spam. Unsubscribe anytime. · Or download the Director's AI Question Pack — 25 questions free