Interim CISO Post-Breach. The First 30 Days to Stabilize Risk, Restore Trust, and Prevent a Second Hit
Interim CISO Post-Breach? Your first 30 days: contain fast, protect evidence, lock down identity, update execs daily, and prove control by day 30.


You didn't walk into a clean environment. You inherited a live crisis, anxious executives, a tired team, and an unknown blast radius. Everyone wants answers, and they want them now. Meanwhile, attackers often try to come back, sometimes using the same doors, sometimes using the doors you didn't know existed.
As an Interim CISO Post Breach—a Chief Information Security Officer role focused on crisis response—your job in the first 30 days isn't perfect security. It's controlled recovery. You stabilize risk fast, protect evidence, keep the business moving, and restore trust with clear, consistent cybersecurity leadership.
You'll balance speed with proof, because guesses create legal and reputation problems. You'll also balance business continuity with containment, because shutting everything down can become its own crisis. In data breach recovery, the goal is simple: stop the bleeding, learn the truth you can defend, fix what matters most, and show measurable control by day 30.
Key takeaways you can act on today
Implement the containment phase of your Incident Response Plan first, then clean up, because attackers love second chances.
Establish a single source of truth for facts, decisions, and timelines.
Lock down Identity and Access Management and privileged access, because that's the fastest path back in.
Patch the easiest re-use paths, especially email, VPN, endpoints, and cloud admin.
Tighten vendor and remote access immediately, then validate it with logs.
Run daily executive updates that state the current Business Risk, business impact, and decisions needed.
Prepare now for regulator and customer questions, and keep answers consistent.
Days 1 to 7: Stop the bleeding, protect evidence, and set clear control
The first week is about reducing uncertainty. You make fast calls, you document everything, and you set a calm operating rhythm. If you hesitate, your team will improvise, and that's when mistakes pile up.
Start by defining what "safe enough to operate" means for the next seven days. That might sound uncomfortable, but it's honest. You're trying to prevent a second ransomware attack while keeping revenue, patient care, shipments, or services running.
At the same time, you protect evidence. Breach response isn't just technical work; it's also legal exposure (including personal liability and cyber liability insurance), customer trust, and sometimes law enforcement. If you don't preserve logs, images, and timestamps correctly, you lose the ability to prove what happened.
You also reduce noise. People will propose big projects because they feel powerless. In week one, big projects often slow you down. You want a short list of actions that cut risk now, with clear owners and daily progress.
The first week isn't about being right. It's about being controlled, consistent, and hard to hit twice.
Lock down access fast so attackers cannot come back
Attackers come back through identity more often than you want to admit. So you start there, even if it feels disruptive.
Prioritize credential management by rotating credentials that matter. That includes privileged accounts, service accounts tied to critical systems, API keys, and any secrets found in code repositories or build tools. Next, reset high-risk user accounts, especially executives, finance, IT admins, and anyone with broad access. Disable stale accounts and remove old vendor users, because forgotten access is a favorite entry point.
If you can't roll out MFA everywhere quickly, you still can make smart choices. Prioritize MFA on email, VPN, remote desktop gateways, admin consoles, and cloud control planes. Those are the keys to the kingdom. Then tighten conditional access, block risky geographies if it fits your business, and require stronger verification for privileged actions.
Don't ignore "break glass" accounts. You should confirm they exist, confirm who can use them, and confirm they're monitored. A break glass account that no one watches is a hidden back door.
Finally, isolate your admin tools. Limit access to domain controllers, password vaults, EDR consoles, and cloud tenant admin portals to a small set of hardened workstations. If you can't do that, at least restrict by network and require stronger sign-in rules.
Get your incident command rhythm working in 24 hours
A breach without clear roles becomes a rumor mill. So you set a simple incident command model and you keep it steady.
You name an incident commander (one person who runs the clock), a security lead, an IT operations lead, legal, communications, HR (if employee data is involved), and a business owner who can make tradeoffs. Then you set a cadence: a short daily standup, a decision log that captures who decided what and why, and a daily executive update for C-suite executives that stays consistent.
Just as important, you define what you will not do. You will not guess in writing. You will not publish unapproved statements. You will not let teams "fix" systems in ways that destroy evidence.
Outside counsel and forensics often matter early. Counsel can protect sensitive work under privilege, and forensics can confirm attacker behaviors without contaminating evidence. If you bring in help, preserve chain of custody. That means controlled access, timestamps, secure storage, and clear documentation of every system image and log export.
Days 8 to 15: Find the real root cause, then fix the paths that matter most
Week two is where you move from firefighting to clarity. You still keep containment tight, but now you work toward a story you can defend. Executives don't just need a list of technical findings. They need a narrative that explains scope, confidence, and business impact.
This is also where many organizations make a costly mistake: they fix what's loud, not what's risky. Attackers don't care about your ticket queue. They care about repeatable paths, hidden trust relationships, and weak identity controls.
So you develop a Remediation Plan that focuses on the few actions that shrink blast radius quickly. You also start building proof that you're regaining control, because customers and regulators will ask what changed.
If you want a steady stream of board-friendly framing for the Board of Directors during this phase with Strategic Alignment, you can pull from CISO insights on the business side of cybersecurity and align your updates to the same practical tone.
Turn messy facts into a clean story you can defend
You build a timeline like a courtroom exhibit, not a hallway conversation. Start with scope, then work backward and forward: suspected entry point, initial execution, persistence, privilege changes, lateral movement, and data touched.
Make your confidence explicit. Separate confirmed facts (proven by logs or artifacts) from strong indicators (signals that usually correlate with compromise), and open questions (what you still can't prove). Leaders can handle uncertainty when you label it clearly.
Evidence collection should be deliberate. You typically pull endpoint telemetry (EDR), identity logs (SSO, IAM, AD), email logs, cloud activity logs, firewall and proxy logs, DNS, and backup system logs. You also capture key system images when needed, especially on servers that show persistence or unusual admin activity.
Mapping your findings to a simple Risk Management Framework view can help. A light NIST-style structure (identify, protect, detect, respond, recover) gives executives a familiar way to understand gaps without drowning them in detail.
Prioritize remediation like a business: top risks, fastest reductions
You don't have time to fix everything, and pretending you do will break trust. Instead, you pick remediation based on four outcomes: stop re-entry, reduce blast radius, protect crown jewels, and reduce fraud risk.
That often means you fix exposed VPN issues first, harden email authentication and inbox rules, patch Technical Vulnerabilities in internet-facing systems, and remove local admin rights where feasible. In many SaaS-heavy environments, you also review risky OAuth apps and third-party integrations, because an attacker can keep access without "hacking" again.
Segmentation matters too, but do it carefully. A rushed network change can cause outages. Start with the most sensitive zones and the most abused management paths.
Track remediation like you would a revenue-critical project. Every fix needs an owner, a due date, a verification step, and a documented exception process. If a business unit can't meet a deadline, you don't accept vague reasons. You capture the risk, the compensating control, and the date you'll revisit it.
Days 16 to 30: Restore trust with stakeholders and harden for the next attack
By week three, people expect progress they can see. Your team also needs relief from constant urgency. So you shift to two tracks: Stakeholder Communication and operational proof.
Trust isn't built with slogans. It's built when your messages stay consistent, your actions match your claims, and your controls show measurable improvement. That's what customers, partners, auditors, and boards are looking for in February 2026, especially with breach fatigue everywhere.
This is also when you prepare for what comes after the first month. You set a 90-day roadmap that finishes the work you started, without turning the organization into a security-only shop.
Communicate with confidence, even when you do not have every answer
Your communications plan should be simple and repeatable: internal staff message, customer and partner updates, board updates, and regulator readiness. Consistency matters more than clever wording.
You speak plainly about what happened, what you did, what you believe is still at risk (if anything), and what changes customers should make. When you don't know something, you say what you're doing to find out, and when you expect to know more.
Use this short prep list before any high-stakes meeting or statement:
Data exposure: What types of data, who is affected, and what you can confirm today.
Downtime: What's restored, what's degraded, and what the next restore step is.
Fraud risk: What you've seen, what you're monitoring, and what customers should watch for.
Regulatory Compliance: Required notifications, current status, and timelines for fulfillment.
Accountability: Which changes you've made to prevent re-entry, and how you'll prove it.
Keep leaders aligned on one rule: no unapproved statements, even if the pressure is intense.
Prove control: the minimum security baseline you must have by day 30
You restore confidence faster when you can point to a baseline that demonstrates cyber resilience and a strengthened security posture, and show it's real. The table below is a practical day 30 baseline you can report to executives and the board.

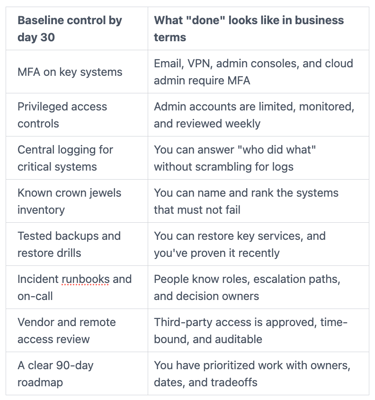
If you need interim leadership to drive this under pressure, Virtual CISO Services from an experienced Chief Information Security Officer can keep decisions moving while your team recovers and executes.
FAQs Leaders Ask an Interim CISO Post Breach
How do you prevent a second hit while teams are still recovering?
You focus on moves that stop re-entry without burning out your people. First, you lock down identity, rotate critical credentials, and tighten privileged access. Next, you monitor for re-entry using identity and endpoint signals, not just firewall alerts. Then you isolate high-value systems from broad admin paths. You also restrict vendor access and validate it through logs. Finally, you confirm backups work, reinforce Security Awareness Programs, and review daily risk in a short executive cadence.
When can you say the incident is contained?
You can say "contained" when you see no new attacker activity, you've closed the entry points you believe were used, and you've added monitoring that would detect a return quickly. You also want validated Governance Risk and Compliance controls in the highest-risk areas, especially identity, remote access, and admin tooling. Still, you avoid absolute claims. Instead, you communicate confidence levels with CISO Accountability and what would change your view, because that's defensible and honest.
Do you have to shut systems down to be safe?
Not always. You shut systems down when the risk is high and you can't reduce it fast enough with controls. For example, active data theft, active encryption, or confirmed admin compromise may require hard stops. When you can't justify a full shutdown, you use alternatives: isolate systems, apply temporary access limits, increase monitoring, and restore in stages. The best model, often advised by a Fractional CISO, is business-driven, based on impact and the speed of risk reduction.
Conclusion
The first 30 days after a breach aren't about heroics. They're about leadership that stays steady when everyone feels shaken. You stabilize risk first, investigate with discipline, remediate the paths that matter, and rebuild trust with proof, not promises. Then you set a realistic 90-day plan that includes post-mortem analysis to finish the hard work without stalling the business.
Speed matters, but evidence matters too, because you'll be judged on what you can support later under CISO accountability. If your organization needs a calm operator who can translate risk into decisions amid CISO burnout, short average CISO tenure, and budget mismanagement, it may be time to bring in interim help and set a clear recovery path. You'll know you chose well when the next month feels controlled, not chaotic.
Tyson Martin is the executive public and pre-IPO companies in financial services, AI/data, SaaS, and cloud hire to make trust a measurable asset, one accountable answer to Is it secure? Is it resilient? Is the AI governed?
© 2026. All rights reserved.
Navigation
Free Resources
Contact
Stay ahead of your next board agenda
Sign up for Reports & Learnings From the Boardroom. Plain-English AI and cyber governance insights, biweekly. No pitch.
No spam. Unsubscribe anytime. · Or download the Director's AI Question Pack — 25 questions free