
Introduction
Picture this: a ransomware alert fires at 2 a.m. By 6 a.m., the security team has confirmed it's real. By 9 a.m., the CEO is in a conference room with legal, IT, and communications—and nobody can agree on who has authority to take the payment systems offline.
The incident response plan exists. It's in a binder. Nobody has read it in 18 months.
This is the gap between incident readiness and incident response. The terms get used interchangeably, but they represent different disciplines, with different owners and fundamentally different consequences when they fail.
Understanding the distinction matters most before an incident — not during one, when every hour of confusion has a price tag and a regulator watching.
Key Takeaways
- Incident readiness is proactive: plans, governance structures, decision rights, trained teams, and tested playbooks built before a threat arrives.
- Incident response is reactive: the live work of detecting, containing, and recovering from an incident — executed under pressure with incomplete information.
- Most organizations underinvest in readiness and overestimate response capability because they've never stress-tested the plan.
- Strong readiness makes response faster and more defensible. Lessons from response feed back into stronger readiness.
- Boards play different roles in each: governance and oversight in readiness, escalation and decision authority in response.
Incident Readiness vs. Incident Response: A Quick Comparison
| Dimension | Incident Readiness | Incident Response |
|---|---|---|
| Timing | Before an incident | During and after an incident |
| Focus | Preparation and governance | Containment and recovery |
| Primary Ownership | Board, CISO, cross-functional leadership | Security and IT teams with defined escalation to leadership |
| Key Activities | Planning, training, tabletop exercises, policy development | Detection, containment, eradication, post-incident review |
| Measurability | Plan completeness, exercise outcomes, gap closure | Mean time to detect/contain/recover, breach cost |

Both disciplines are essential. Clarifying which phase each addresses helps organizations invest appropriately and assign accountability where it actually belongs.
What Is Incident Readiness?
Incident readiness is an organization's state of preparedness before a cyber incident occurs. It includes the plans, governance structures, trained teams, communication protocols, and tested capabilities that determine how well the organization will perform when a real threat unfolds.
The critical distinction: readiness is not a document. It's a demonstrated, inspectable capability.
Core Components of a Mature Readiness Program
A well-built readiness program includes:
- A formalized Incident Response Plan (IRP) with clearly defined roles, responsibilities, and named alternates
- Role-specific playbooks for ransomware, data breach, insider threat, and other high-probability scenarios
- Documented decision rights and escalation thresholds that specify who authorizes what action at what severity level—pre-decided, not improvised
- A crisis communications plan covering internal and external stakeholders, including customers, regulators, and the board
How Readiness Gets Validated
Plans without testing are assumptions. CISA guidance recommends quarterly IRP reviews and regular tabletop exercises to rehearse response before an incident occurs. The reality, however, is that most organizations don't follow that cadence.
A 2024 Ponemon/Sullivan survey of 650 U.S. IT and cybersecurity practitioners found that only 23% reviewed and tested their incident response plan quarterly. Another 15% tested it just once per year. More troubling: only 46% had a plan applied consistently across the enterprise—17% described their plan as ad hoc.
Those gaps are exactly what simulation is designed to close:
- Executive tabletop exercises test governance and escalation, not just technical workflows
- Technical simulations stress-test detection and containment capabilities under realistic conditions
- After-action reviews generate concrete improvement actions with named owners and deadlines

The Governance Dimension Most Organizations Miss
Boards and executives are not passive observers of readiness. They set risk tolerance, approve resources, review exercise outcomes, and must understand exactly what decisions will reach them during a real incident.
Without clear decision rights established during readiness, leadership improvises under pressure. The worst decisions in incident history weren't made by bad people. They were made by capable people who didn't know what they were authorized to decide.
Building these structures — decision rights, escalation thresholds, execution frameworks you can audit — is where Tyson Martin focuses when working with boards and executive teams. For organizations navigating leadership transitions, regulatory scrutiny, or first-time maturity assessments, the governance layer is usually the most urgent gap to close.
Where Readiness Investment Is Most Critical
Organizations with the highest readiness urgency include:
- Companies entering new regulatory environments (SEC cybersecurity disclosure rules, HIPAA, financial services requirements)
- Businesses undergoing M&A due diligence, where cyber posture is evaluated and readiness gaps affect deal value
- Enterprises that experienced a prior incident and need to close documented gaps before the next one
- Boards preparing for annual cyber oversight reviews or responding to increased director scrutiny
The signal that readiness is working isn't that nothing goes wrong. It's that when something does go wrong, every stakeholder knows their role, the first hour is structured rather than chaotic, and the board can ask informed questions rather than reactive ones.
What Is Incident Response?
Incident response is the active, real-time process of detecting, containing, eradicating, and recovering from a security incident once it's confirmed. What separates it from readiness is its reactive, time-compressed nature: decisions are made under pressure, often with incomplete information, and the quality of those decisions directly determines how much damage the organization sustains.
The NIST Incident Response Lifecycle
The original NIST SP 800-61 framework defines four phases that most response teams still work from:
- Preparation — building and training the response team, acquiring tools, securing systems (this phase overlaps directly with readiness)
- Detection and Analysis — identifying whether an incident occurred and determining its type, scope, and magnitude
- Containment, Eradication, and Recovery — isolating the threat, removing malicious components, restoring systems to normal operation
- Post-Incident Activity — lessons-learned review, plan updates, and data to improve future response
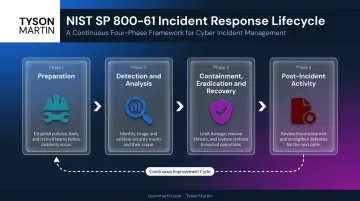
Preparation bridges directly into readiness. These two disciplines are linked, not separate silos.
What Effective Response Looks Like in Practice
When an incident is declared, an organization with mature readiness moves quickly and predictably:
- A pre-assigned incident commander takes operational control immediately
- Communication follows a defined protocol — internal and external, no ad hoc statements
- Affected systems are isolated per playbook, not via informal consensus
- Forensic evidence is preserved before well-intentioned cleanup erases what's needed to understand the breach
- Escalation to leadership occurs at pre-defined thresholds, not when someone decides it "feels" serious enough
The financial stakes of doing this poorly are significant. IBM's Cost of a Data Breach research found that organizations with a formal IR team and incident response plans reduced breach cost by an average of $473,706 compared to those without. Organizations that detect breaches internally (rather than learning from the attacker) shorten the breach lifecycle by 61 days and save nearly $1 million.
The Organizational Dynamics During Active Response
Security teams lead technical containment. But executive leadership becomes a critical stakeholder within hours when decisions involve:
- Triggering the SEC's four-business-day disclosure clock once materiality is determined
- Approving customer notification language and public communications
- Deciding whether to engage law enforcement and on what terms
- Weighing business continuity tradeoffs — which systems come offline, and for how long
Pre-established decision rights either hold or collapse at this moment. Without prior governance work, executives spend the first critical hours negotiating authority instead of exercising it.
Post-Incident Review as the Feedback Loop
Post-incident review isn't a formality. It's the mechanism that converts a painful experience into operational improvement. A rigorous after-action output covers:
- A timeline of events as they actually unfolded
- Decisions made during the incident and the rationale behind them
- Evidence preserved and chain of custody documentation
- Customer impact assessment
- A funded remediation plan with named owners and target dates
Organizations that skip this analysis don't just miss a learning opportunity — they carry unresolved risk directly into the next event.
Why the Two Get Confused—and Why That Matters
The most common version of this problem looks like this: a capable security team, a documented incident response plan, and genuine confidence that the organization is prepared. In practice, though:
- The plan hasn't been tested in two years
- Key personnel have changed
- Decision rights were never formally established
- Nobody has verified that the communication protocols still work
That's response capability without readiness.
The opposite failure is equally dangerous: organizations that invest in readiness activities—plans, training, tabletops—but treat them as compliance checkboxes. The plan exists, the exercise happened, the box is checked. But the exercise involved only the security team, the plan doesn't reflect current personnel, and no action items from the last tabletop were ever closed.
The same Ponemon/Sullivan survey found that only 50% of organizations with an incident response plan considered it effective or highly effective. Half of organizations with a plan don't trust their own plan. That's not a readiness program—it's documentation with an expiration date.
The Board-Level Consequence
When readiness and response are poorly integrated, the board ends up making consequential decisions—whether to pay a ransom, when to notify regulators, how to communicate with customers—without prior alignment on risk tolerance or decision authority. The incident becomes a governance crisis stacked on top of a security crisis.
NACD guidance specifically calls for boards to confirm clear escalation thresholds for ransomware decision authority before an incident occurs—including whether management or the board holds authority to approve a ransom payment. That decision should never be made for the first time under a deadline.
The Practical Diagnostic
Two diagnostic questions cut through the confusion quickly:
- For organizations with strong readiness that haven't stress-tested it: Prioritize executive and board-level tabletop exercises that force real tradeoffs—shutdown decisions, disclosure timing, customer communications—not just technical walkthroughs.
- For organizations that have experienced an incident without a rigorous post-incident review: That unresolved analysis is active risk. The gaps identified during the incident haven't been closed; they've just been forgotten.
The right question is never "do we have a plan?" It's whether that plan has ever been tested under pressure.
Closing the Gap: What Boards and Executives Should Do Next
Three concrete actions for executive leadership:
Commission a readiness assessment that goes beyond document review. Evaluate whether teams can actually execute the plan—roles named with alternates, escalation paths that work under pressure, backups that have been tested with an actual restore, communication protocols that don't depend on people who left the company last year.
Establish or validate decision rights and escalation thresholds. Before the next incident, the board should know: who can declare a material incident, who can authorize system shutdowns that affect revenue, who approves external communications, and at what threshold does the incident require board-level action. These decisions need to be documented, tested, and owned—not improvised.
Treat post-incident review as a governance deliverable. The board should receive a structured after-action report—timeline of events, decisions made, evidence preserved, customer impact, remediation plan with owners and dates. A verbal debrief is not governance.

Readiness and response depend on each other. A polished plan that collapses under pressure provides the same protection as no plan at all. Decision clarity before the incident is what makes execution defensible during it.
For boards and executive teams looking to assess where they actually stand, Tyson Martin works as a board advisor and interim CISO to close real gaps: clear decision rights, inspectable readiness programs, and a 90-day plan with named owners and measurable outcomes. Connect directly via LinkedIn to start the conversation.
Frequently Asked Questions
What are the stages of incident response?
The NIST framework defines four phases: Preparation, Detection and Analysis, Containment/Eradication/Recovery, and Post-Incident Activity. Preparation bridges directly into incident readiness—it's the structural link between the two disciplines.
What is the difference between incident readiness and incident response?
Readiness is proactive: plans, governance, decision rights, and tested capabilities built before a threat arrives. Response is reactive: the real-time execution of containment and recovery once an incident is confirmed.
Who is responsible for incident readiness in an organization?
Readiness is cross-functional. The CISO and security leadership own technical preparation—plans, playbooks, and detection capabilities. Executive leadership and the board own the governance layer: approving risk tolerance, resourcing the program, and establishing the decision rights that hold under pressure.
How often should organizations test their incident response plans?
At minimum, annual executive-level tabletop exercises and more frequent technical simulations. Plan reviews should also be triggered by personnel changes, new regulatory requirements, or after any real incident—not just on a calendar schedule.
What should a board ask about incident readiness?
Has the plan been tested in the past 12 months? Who is authorized to make which decisions during an active incident? What specific action items came out of the last exercise or real incident—and were they actually closed?


