
An incident response playbook is a threat-specific, pre-approved set of procedures that tells your team exactly who does what, in what order, when a particular type of cyber incident occurs. This guide is written for boards, executive teams, CISOs, general counsel, and risk leaders in regulated industries — not just technical responders. When a significant incident hits, governance gaps surface faster than technical ones.
The 2024 IBM Cost of a Data Breach Report puts the global average breach cost at $4.88M, with financial-sector firms averaging $6.08M and 168 days just to identify a breach. What follows explains what a real playbook contains, how it functions across the incident response lifecycle, and what separates playbooks that hold under pressure from those that collapse.
Key Takeaways
- An incident response playbook is threat-specific and tactical — distinct from the broader incident response plan and from operational runbooks
- Effective playbooks define incident classification, roles, escalation thresholds, communication protocols, and evidence-preservation rules
- NIST SP 800-61 defines four phases — from Preparation through Post-Incident Activity — and remains the dominant structural reference
- The most common failure point is not the absence of a playbook — it's the gap between what's written and what actually happens under pressure
- Real readiness means decision rights are clear, responses are practiced, and recovery is verifiable — not just documented
Playbook, Plan, and Runbook: Understanding the Difference
Most organizations conflate three distinct documents, and that confusion creates accountability gaps when an incident requires immediate cross-functional action.
The three-tier model:
- Incident response policy — sets governance rules and executive accountability
- Incident response plan — the organization's overarching strategy covering the full lifecycle of any incident; CISA defines it as a formally approved written document that helps the organization before, during, and after a cybersecurity incident
- Incident response playbook — threat-specific, step-by-step tactical guidance for a single scenario (ransomware, data breach, insider threat, etc.)

Think of the plan as the constitution and each playbook as the legislation for a specific situation. One governs the whole; the other governs the moment.
Where Runbooks Fit
A runbook is an operational checklist for routine or repeatable tasks — system restarts, patch procedures, backup verification. Runbooks don't govern coordinated crisis response; they document how to execute specific technical steps.
Runbooks often serve as reference documents within a playbook, linked at the steps where a technician needs procedural detail.
When a single document tries to serve all three functions, responders arrive at a crisis without clear authority, without knowing who escalates to whom, and without scenario-specific steps that match what they're facing. That's not a terminology problem — it's an execution failure waiting to happen.
A mature organization maintains multiple playbooks — one per major threat scenario — all anchored to a single incident response plan. HHS recommends tailored, scenario-specific playbooks as components within the broader IRP, not as replacements for it.
Core Components of an Effective Incident Response Playbook
Every playbook, regardless of threat type, must include the following elements.
Incident Definition and Severity Classification
Without clear classification criteria, teams waste critical time debating whether an event even constitutes an incident. NIST SP 800-61 recommends categorizing incidents across three dimensions:
- Functional impact — None, Low, Medium, or High effect on operations
- Information impact — None, Privacy Breach, Proprietary Breach, or Integrity Loss
- Recoverability effort — Regular, Supplemented, Extended, or Not Recoverable
Map these categories to your internal P1/P2/P3 tiers with explicit criteria. The classification threshold triggers everything else — escalation, notification, and containment authority.
Roles and Responsibilities
Pre-designating roles is what allows teams to act without waiting for approval chains that slow containment. Every playbook should name:
- Incident commander — overall coordination and executive liaison
- Technical lead — responsible for the quality of technical response work
- Communications manager — controls internal and external messaging
- Legal/compliance liaison — advises on breach notification obligations and evidence preservation
Each role requires a named backup. Tyson Martin's advisory work specifically addresses the gap organizations face without a dedicated CISO: establishing decision rights in advance so that "who leads, who decides, who talks" is never ambiguous when the incident clock is running.
Communication Protocols
This section carries the most regulatory exposure for regulated entities. It must define:
- Internal thresholds — when executives and the board are notified (tied to impact level, not certainty)
- External protocols — who is authorized to speak to regulators, customers, law enforcement, and cyber insurance carriers
- Pre-approved templates — drafted messages for each audience, reviewed by legal before any incident occurs
- Out-of-band channels — alternate communication paths in case primary systems are compromised
Notification deadlines leave no room for ambiguity. SEC material incident disclosures are generally due within four business days of materiality determination. HIPAA breaches affecting 500 or more individuals must be reported to HHS within 60 calendar days of discovery. FTC Safeguards Rule notifications are due within 30 days for qualifying events involving at least 500 consumers. All 50 states, plus DC and US territories, have their own breach notification laws.

Documentation and Evidence Preservation
Courts, regulators, and insurers will scrutinize what was captured and when. The playbook must specify:
- Chain-of-custody procedures — who controls evidence, with signed handoffs at each transfer
- Hash verification — cryptographic integrity checks on forensic images and log exports
- Timestamped activity logs — every containment and remediation action recorded in real time
- Legal hold triggers — criteria that automatically notify counsel to preserve relevant data
- Evidence ownership — one named individual accountable for the complete evidence record
Scenario-Specific Playbooks to Maintain
Playbook prioritization should be risk-register driven, not template driven. That said, regulated industries should maintain playbooks covering at minimum:
- Ransomware/extortion — appeared in 32% of breaches per the 2024 Verizon DBIR
- Data breach/data loss
- Phishing and social engineering — involved in 68% of breaches as the primary human element
- Insider threat — internal actors responsible for 70% of healthcare breaches per Verizon
- Denial-of-service
- Zero-day vulnerability exploitation
The Incident Response Lifecycle: How a Playbook Guides Each Phase
NIST SP 800-61 defines four official phases of incident response. Many organizations describe a six-phase model by splitting Containment, Eradication, and Recovery into separate phases — operationally useful, but not the official NIST structure. NIST SP 800-61 Rev. 3 (published April 3, 2025) supersedes Rev. 2 and aligns incident response recommendations with the CSF 2.0 framework.
Each phase below maps directly to where a playbook fills the gaps that a general incident response plan leaves open.
Phase 1: Preparation
Preparation happens before any incident — and it's where the playbook itself is built, tested, and maintained. This phase includes:
- Equipping response teams with tools, access, and current contact directories
- Running tabletop exercises with executives, legal, and communications — not just IT
- Securing executive sign-off on escalation thresholds in writing
- Pre-deciding critical authorities: who can take systems offline, who approves emergency spend, who speaks externally

Playbooks without executive sign-off leave responders negotiating authority during containment. Tyson Martin's preparation work produces an updated incident response plan with named roles, escalation rules, and current contact lists — and concludes every tabletop exercise with a short action list that includes an owner, a due date, and the risk if that action slips.
Phase 2: Detection and Analysis
The playbook defines how alerts are triaged, what evidence is collected, how severity is confirmed, and when escalation is triggered. Ambiguity here causes the most costly delays.
What must be explicit:
- What distinguishes a confirmed incident from a suspicious event
- Who confirms the classification and within what timeframe
- What evidence is preserved from the moment of detection
Financial firms average 168 days to identify a breach and 51 days to contain it. Much of that delay starts in this phase.
Phase 3: Containment, Eradication, and Recovery
NIST treats these as a single phase; operationally, they involve distinct steps that the playbook must address separately.
Containment covers both immediate and longer-term actions. The playbook must define who has authority to take systems offline — a decision with direct revenue impact that typically requires executive-level approval. Immediate steps include:
- Isolating affected systems
- Revoking compromised credentials
- Blocking malicious traffic
- Deploying network segmentation and backup systems
Eradication means removing malware, closing exploited vulnerabilities, and eliminating unauthorized access. Verification steps belong in the playbook — confirmed, not assumed. SANS 2023 data found 43% of respondents faced returning threat actors using the same or similar tactics, a direct consequence of incomplete eradication.
Recovery governs the sequence for bringing systems back online, validation steps confirming integrity, and monitoring requirements post-restoration. Premature recovery is one of the most expensive mistakes in incident response. The playbook must also address communicating recovery status to stakeholders and regulatory bodies where required.
Phase 4: Post-Incident Activity
The post-incident review is where the playbook proves its value — and where it gets updated for next time. It should produce:
- Timeline of events and decisions made
- Root cause analysis and control gaps identified
- Evidence preserved with chain of custody documented
- Funded remediation plan with owners, costs, and dates
- Playbook updates before the next incident occurs
For regulated industries, this phase also involves formal reporting obligations. Board-level documentation may be required — and what gets documented during the review matters for regulatory defensibility.
Common Playbook Mistakes That Create Governance Risk
Confusing Documentation With Readiness
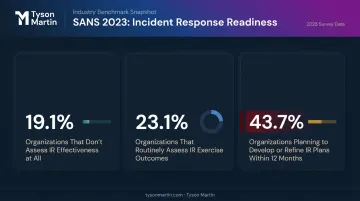
The most damaging misconception: a documented playbook equals preparedness. SANS 2023 found 19.1% of organizations don't assess the effectiveness or maturity of their IR processes at all. Only 23.1% routinely assess outcomes from IR exercises. Another 43.7% planned to develop or refine their IR plans or playbooks in the next 12 months — meaning they know they're not ready.
A document is not readiness. Readiness means teams know their roles without looking them up, decision rights are settled before the incident starts, and recovery has been tested against something real.
Writing Playbooks Only for Technical Teams
When escalation language, notification thresholds, and decision authorities aren't clearly defined for executives and legal counsel, the playbook breaks down at exactly the moment it matters most: when a major incident demands cross-functional action.
Organizations without a dedicated CISO are especially exposed. Without someone who can translate technical findings into executive decisions, governance gaps surface fast — and the playbook becomes a document no one at the table knows how to use.
One Generic Playbook for All Incidents
A ransomware response looks nothing like a data breach response. The steps, communication requirements, regulatory obligations, and recovery timelines are fundamentally different. One generic document can't serve all scenarios — and attempting to use one creates dangerous ambiguity about which procedures actually apply.
Treating Playbooks as Static Documents
Organizations that stop updating their playbooks after incidents, technology changes, or regulatory updates are effectively rehearsing an outdated response. Industry practice calls for review at minimum twice per year and after every significant incident. NIST's Post-Incident Activity phase makes this a requirement, not a suggestion: continuous improvement through lessons learned is built into the framework.
Best Practices for Building a Board-Ready Playbook
What "Board-Ready" Actually Means
A board-ready playbook isn't longer or more detailed — it's more precise about governance. It must include:
- Documented executive sign-off on escalation thresholds before any incident occurs
- Board notification thresholds tied to impact, not certainty (for example, briefing within hours of confirmed ransomware, then updating on a fixed cadence)
- Plain-English reporting language that answers what happened, what's impacted, what's being done, and what decisions are needed
- Regulatory deadline mapping — SEC's four-business-day window, HIPAA's 60-day clock, FTC's 30-day trigger, and applicable state laws

For boards in financial services, healthcare, or retail, the gap between a documented playbook and one that holds under pressure is almost always an execution gap — not a documentation one. Independent validation of how the playbook actually runs is what separates a defensible posture from a paper exercise.
Tabletop Exercises: Who Must Be in the Room
Tabletop exercises validate whether the playbook actually works. Participation must extend beyond IT to include:
- CEO or designated executive sponsor
- General counsel and privacy counsel
- Chief communications or marketing officer
- Compliance and risk leadership
- Board representatives for significant scenarios
Prioritize scenarios that force real tradeoffs: ransomware with partial backups, cloud identity compromise, third-party outage stopping revenue, and data leak extortion. Each exercise should function as a decision drill — practicing shutdown calls, statement timing, customer notifications, and regulator notifications under realistic pressure.
**Every exercise must close with a short action list** — owner, due date, and the risk if that item slips. Without follow-up to closure, tabletops become theater.
Integration Requirements
An effective playbook doesn't exist in isolation. It must align with:
- Cyber insurance policy requirements — misalignment surfaces during claims
- Business continuity plan — recovery sequence and system restoration priorities must be consistent
- Third-party breach notification obligations — vendor contracts may carry their own notification triggers
- SIEM/SOAR tooling — detection thresholds and automated containment actions should match what the playbook prescribes
Cyber insurance premiums also increase when organizations can't demonstrate tested security controls. That makes playbook validation a financial governance issue with direct board accountability — not a task to delegate entirely to the security team.
Frequently Asked Questions
What is an incident response playbook?
An incident response playbook is a threat-specific, pre-approved tactical guide that tells response teams who does what and in what order during a particular type of security incident. It's distinct from the broader incident response plan, which covers all incident types at a strategic level.
What are the steps in an incident response playbook?
Playbooks follow the NIST SP 800-61 lifecycle: Preparation; Detection and Analysis; Containment, Eradication, and Recovery; and Post-Incident Activity. Each playbook tailors those phases to a specific threat scenario, with named roles, decision thresholds, and phase-specific procedures.
What are the 5 C's of incident management?
No authoritative body — NIST, CISA, or SANS — has standardized a "5 C's" framework for incident management. Conflicting versions circulate from non-authoritative sources. For playbook structure you can defend to auditors and regulators, rely on NIST SP 800-61 or CISA's IRP guidance instead.
How is an incident response playbook different from an incident response plan?
The plan is the organization's overarching governance document covering strategy, lifecycle, and roles for all incidents. Each playbook provides specific, actionable steps for a single threat scenario — ransomware or a data breach — with scenario-specific communication requirements and regulatory obligations.
How often should an incident response playbook be updated?
Industry best practice calls for review at minimum twice per year and after every significant incident, technology change, or relevant regulatory update. NIST's Post-Incident Activity phase explicitly supports using lessons learned to improve future handling.
Who is responsible for maintaining an incident response playbook?
The CISO or equivalent security leader typically owns the playbook, but effective maintenance requires active input from legal, compliance, IT, communications, and executive leadership. Escalation thresholds and notification requirements must reflect current authority — that only happens with cross-functional sign-off.


